Note
Go to the end to download the full example code.
Working with tetrodes
Tetrodes are a common recording method for electrophysiological data. It is also common to record from several tetrodes at the same time. In this ‘how to’ we’ll see how to work with data from two tetrodes, each with four channels.
We’ll start by importing some functions we’ll use in this How To guide
import spikeinterface.preprocessing as spre
from spikeinterface.widgets import plot_traces, plot_probe_map
from spikeinterface import generate_ground_truth_recording
from probeinterface import generate_tetrode, ProbeGroup
In practice, you would read in your raw data from a file. Instead, we will generate a recording with eight channels. We can also set a duration, number of units and sampling frequency.
recording, _ = generate_ground_truth_recording(
durations = [60], # make the recording 60s long
sampling_frequency=30_000,
num_channels=8,
num_units=10,
)
We now need to define the probe. This will tell the recording which channels came from
which tetrode. To do this, we will use the generate_tetrode function from ProbeInterface
to generate two 4-channel probes (representing one tetrode each). In our case, since we
don’t know the relative distances between the tetrodes, we will move the second
tetrode away from the first by 100 microns. This is just so we can visualize the
results more easily. Eventually, we will sort each tetrode separately, so their
relative distance won’t affect the results.
# Technically, we will add each tetrode to a :code:`ProbeGroup`. Read more in the ProbeInterface
# docs.
# Create each individual tetrode
tetrode_1 = generate_tetrode()
tetrode_1.create_auto_shape()
tetrode_2 = generate_tetrode()
tetrode_2.move([100, 0])
tetrode_2.create_auto_shape()
# Add the two tetrodes to a ProbeGroup
tetrode_group = ProbeGroup()
tetrode_group.add_probe(tetrode_1)
tetrode_group.add_probe(tetrode_2)
# Now we need to "wire" our tetrodes to ensure that each contact
# can be associated with the correct channel when we attach it
# to the recording. In this example we are just using `range`
# but see ProbeInterface for more tutorials on wiring
tetrode_group.set_global_device_channel_indices(range(8))
We can now attach the tetrode_group to our recording. To check if this worked, we’ll
plot the probe map
recording_with_probe = recording.set_probegroup(tetrode_group)
plot_probe_map(recording_with_probe)
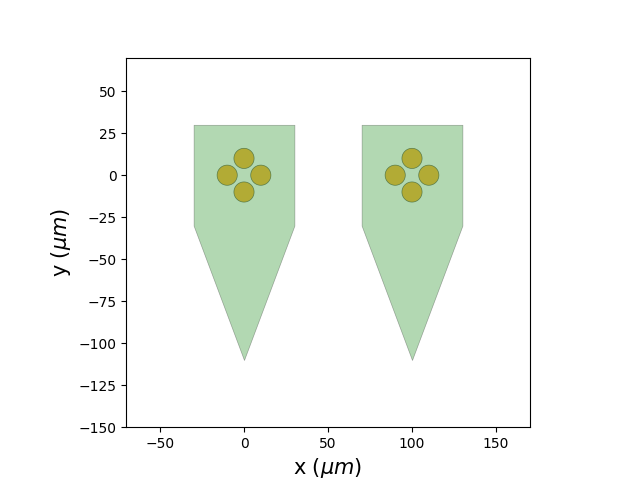
<spikeinterface.widgets.probe_map.ProbeMapWidget object at 0x73e4c4e08fd0>
Looks good! Now that the recording is aware of the probe geometry, we can begin a standard spike sorting pipeline. First, we can apply preprocessing. Note that we apply this preprocessing on the entire bundle of tetrodes.
preprocessed_recording = spre.bandpass_filter(recording_with_probe)
WARNING: a very common preprocessing step is to apply a common median reference. This subtracts the median signal from all channels to help remove noise. However, for a tetrode, a spike is often seen on all channels. So removing the median can remove the entire spike! This is still a danger if you have two tetrodes in a bundle, which might pick up the same spike, but becomes less dangerous as the number of tetrodes in your bundle increases.
Tetrodes often have dead channels, so it is advised to try and detect and remove these. For tetrodes, we should use a detection method which doesn’t depend on the channel locations such as std or mad:
recording_good_channels = spre.detect_and_remove_bad_channels(
preprocessed_recording,
method = "std",
)
It can be a good idea to sort your tetrode data separately for each tetrode.
When we use set_probegroup, the channels are automatically
labelled by which probe in the probe group they belong to. We can access
this labeling using the “group” property.
print(recording_good_channels.get_property("group"))
[0 0 0 0 1 1 1 1]
We can then use this information to split the recording by the group property:
grouped_recordings = recording_good_channels.split_by('group')
print(grouped_recordings)
{0: GroundTruthRecording (ChannelSliceRecording): 4 channels - 30.0kHz - 1 segments
1,800,000 samples - 60.00s (1.00 minutes) - float32 dtype - 27.47 MiB, 1: GroundTruthRecording (ChannelSliceRecording): 4 channels - 30.0kHz - 1 segments
1,800,000 samples - 60.00s (1.00 minutes) - float32 dtype - 27.47 MiB}
Now that we’ve got preprocess, clean data. Let’s take a look at a snippet of data from the first group:
plot_traces(grouped_recordings[0])
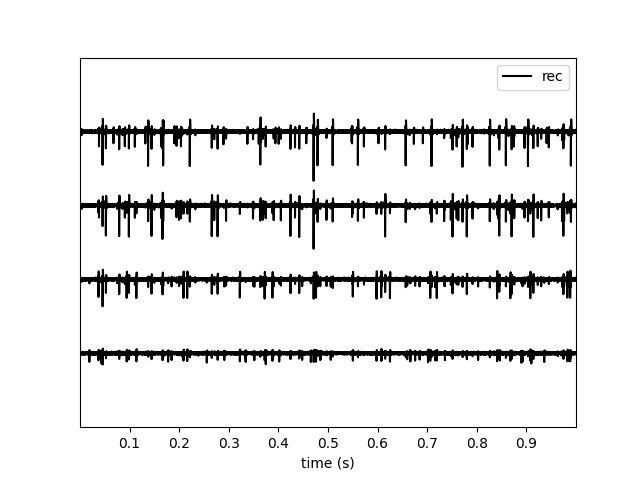
<spikeinterface.widgets.traces.TracesWidget object at 0x73e4c1922440>
Beautiful! We are now ready to sort. To read more about sorting by group, see Sorting a Recording by Channel Group. Note that many modern sorters are designed to sort data from high-density probes and will fail for tetrodes. Please read each spike sorter’s documentation to find out if it is appropriate for tetrodes.
Total running time of the script: (0 minutes 0.632 seconds)